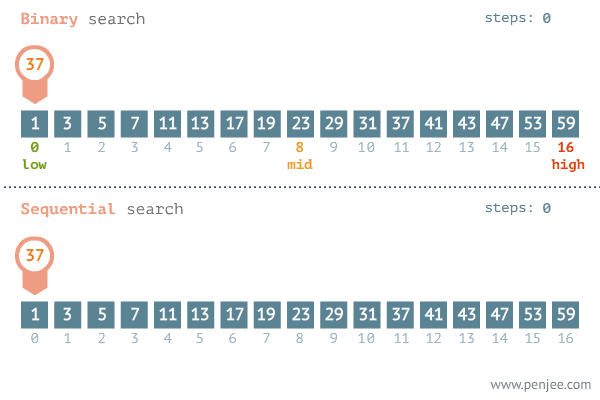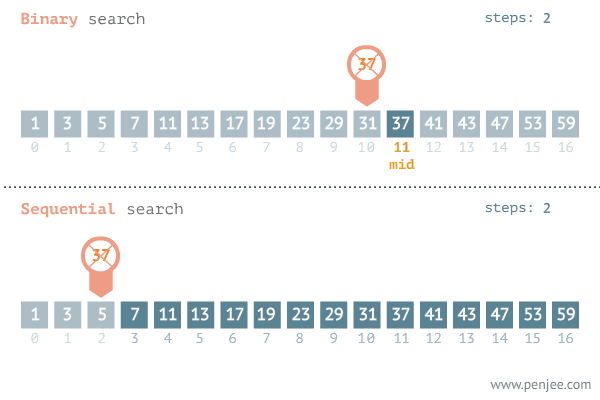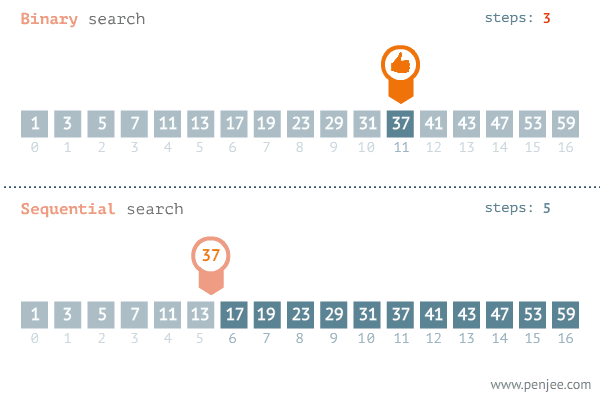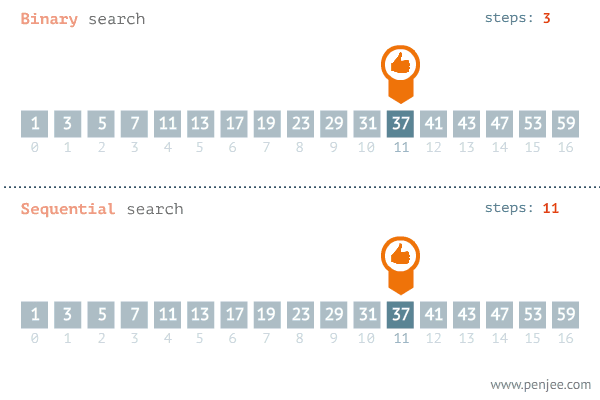
“A common side effect of partitioning a system into a collection of cooperating classes is the need to maintain consistency between related objects. You don’t want to achieve consistency by making the classes tightly coupled, because that reduces their reusability.”
Design Patterns: Elements of Reusable Object-Oriented Software
Active Record Observers are a great tool for when we want to monitor an event occurence and take action, and especially when that event concerns multiple classes.
Active Record callbacks vs. ActiveRecord::Observers
Active Record’s built in callback helper methods can easily hook into the object lifecycle to affect change. However, when callbacks affect objects outside the model, we end up violating the single responsibility principle, so we try to avoid them if we can. Using observers brings back single responsibility to models while still allowing us to still hook into the object lifecycle.
The Observer is a central place outside of the original class to watch for database changes. By extracting that logic outside of the model, we bring back single responsibility and avoid commingling models. Observers only report or take action on a process, and should not affect a process directly.
ActiveRecord::Observer is an implementation of the Observer pattern. It was removed from core in Rails 4.0 but is now available as a gem.
Example: Callbacks
In the example below, we’re referencing MessageMailer in the User class, increasing the User class’s responsibility:
|
|
Example: Observers
Alternatively, by using observers in the example below, we extract the MessageMailer logic out of User and put it in its own class, UserObserver, that watches for an event and dispatches an action accordingly:
|
|
Example: Observing multiple classes
Observers are especially helpful in cases like the below where there are multiple models commingled and we want to hook into all of them to watch for some event. We can pull logic out of models where it doesn’t belong, put it in its own separate place, observe actions, and still affect change as needed.
|
|
AR::Observers and invisibility
One thing to keep in mind with observers is that there is no visible reference to the observer in the observed class. Since we now have unseen side effects that are not readily apparent in our observed class, it can be less clear what’s happening.
When to use AR::Observers
Active Record Observers are useful when we want to stay updated on a certain process, and especially when we have multiple classes involved in an event.
They require very little setup, and since they are Active Record objects, they come rolled up with the functionality of Active Record.
When not to use AR::Observers
It’s also possible to overuse observers. If there is just one thing that happens, we probably don’t need to use observers.
For example, in our first code sample where we send a welcome email after a new user is created, the events are probably simple enough that we don’t actually need an observer. The same use case can be handled by extracting a service object like UserNotifier.
However, if you want mutiple additional actions to take place after the user is created, it may be worth using an observer.
References
Rails::Observers
Giant Robots Smashing Into Other Robots: 13: I’ll disagree in just a little bit
Upcase: The Weekly Iteration: Callbacks
Design Patterns In Ruby
Design Patterns: Elements of Reusable Object-Oriented Software